Which Table Format Do LLMs Understand Best? (Results for 11 Formats)
When discussing the reliability of AI-based systems, there’s something simple that doesn’t get enough attention: what’s the best format for passing tables of data to an LLM?
Should you use markdown tables or CSV?
JSON or YAML?
Or does some other format work better than any of these?
Update (Nov 2025): There’s been a lot of interest lately in a new format called ‘TOON’. We ran the tests below on TOON as well. Here are the TOON results and our wider TOON benchmarks.Why This Question Matters
Many RAG pipelines involve ingesting documents that contain tables of information and feeding that tabular information to an LLM.
System Accuracy
If you’re not formatting tabular information in a way that it is easy for the LLM to consume, then you may be needlessly hurting the accuracy of your overall system.
Token Costs
Some formats can use several times more tokens than others to represent the same data. If you’re paying for the number of tokens you’re processing, your choice of format therefore affects your LLM inference costs.
Our Methodology
We designed a controlled experiment to test how the formatting of a set of data would affect how accurately an LLM could answer questions about that data.
Our tests involved passing 1000 records to an LLM and asking it to answer a question based on the data. We then evaluated whether it answered correctly or not in each case.
We repeated this process for 1000 questions, using each of 11 different data formats.
- Dataset: 1,000 synthetic employee records with 8 attributes each (ID, name, age, city, department, salary, experience, project count)
- Questions: 1,000 randomized queries about specific data points
- Model: GPT-4.1-nano
- Formats Tested: 11 different data representation formats
Example Question-Answer Pairs
Q. "How many years of experience does Grace X413 have? (Return just the number, e.g. '12'.)"
A. "15"Q. "What is Alice W204's salary? (Return just the number, e.g. '85200'.)"
A. "131370"Notes on Methodology
We opted to pass a relatively large number of records to the LLM in order to test its limits. In practice, with a large structured dataset, you’ll often want to chunk it up and/or query it in some way in order to extract just the most relevant records / information and only pass that reduced amount of context to the LLM.
When using formats such as CSV, HTML tables and markdown tables that involve headers, you may want to repeat those headers on a regular basis (e.g. every 100 records) to help with understanding. For simplicity, we didn’t do that here.
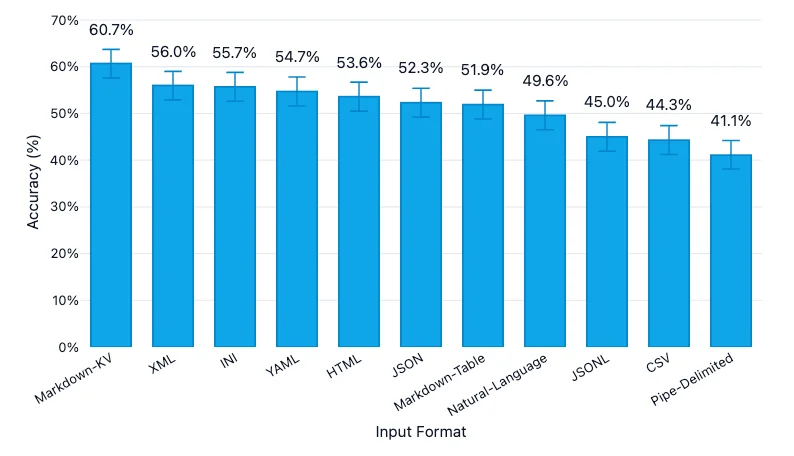
How Well Did the LLM Understand Each Format?
| Format | Accuracy | 95% Confidence Interval | Tokens |
|---|---|---|---|
| Markdown-KV | 60.7% | 57.6% – 63.7% | 52,104 |
| XML | 56.0% | 52.9% – 59.0% | 76,114 |
| INI | 55.7% | 52.6% – 58.8% | 48,100 |
| YAML | 54.7% | 51.6% – 57.8% | 55,395 |
| HTML | 53.6% | 50.5% – 56.7% | 75,204 |
| JSON | 52.3% | 49.2% – 55.4% | 66,396 |
| Markdown-Table | 51.9% | 48.8% – 55.0% | 25,140 |
| Natural-Language | 49.6% | 46.5% – 52.7% | 43,411 |
| JSONL | 45.0% | 41.9% – 48.1% | 54,407 |
| CSV | 44.3% | 41.2% – 47.4% | 19,524 |
| Pipe-Delimited | 41.1% | 38.1% – 44.2% | 43,098 |
Highlights
- Format seems important: we saw significant differences in understanding between the different formats.
- CSV and JSONL performed poorly: suggesting the potential for quick wins if you’re currently using one of these formats by default.
- Markdown-KV came out top, hitting 60.7% accuracy and landing roughly 16 points ahead of CSV. (Markdown-KV is our term for a non-standardised format featuring “key: value” pairs in markdown.)
- Accuracy cost tokens: the top-performing Markdown-KV format used 2.7 times as many tokens as the most token-efficient format, CSV.
Accuracy vs. Token Cost Trade-offs
The chart below visualizes the relationship between accuracy and token usage (on a logarithmic scale). This helps illustrate the trade-offs between these two important metrics:
As you can see, there’s a general trend where more tokens correlate with higher accuracy, but the relationship is far from linear. Some formats punch above their weight (like Markdown-KV), while others are inefficient on both dimensions (like Pipe-Delimited).
Keep Up With AI Agent Research
Subscribe to get the latest findings on improving AI agent accuracy and performance
We respect your privacy. Unsubscribe at any time.
Data Formats Evaluated
1. JSON
[
{
"id": 1,
"name": "Diana A0",
"age": 46,
"city": "London",
"department": "Engineering",
"salary": 141015,
"years_experience": 7,
"project_count": 17
},
{
"id": 2,
"name": "Grace B1",
"age": 59,
"city": "Berlin",
"department": "Engineering",
"salary": 100066,
"years_experience": 11,
"project_count": 32
},
{
"id": 3,
"name": "Grace C2",
"age": 64,
"city": "Dubai",
"department": "Engineering",
"salary": 91727,
"years_experience": 9,
"project_count": 49
}
]2. CSV
id,name,age,city,department,salary,years_experience,project_count
1,Diana A0,46,London,Engineering,141015,7,17
2,Grace B1,59,Berlin,Engineering,100066,11,32
3,Grace C2,64,Dubai,Engineering,91727,9,493. XML
<?xml version="1.0" ?>
<employees>
<employee id="1">
<name>Diana A0</name>
<age>46</age>
<city>London</city>
<department>Engineering</department>
<salary>141015</salary>
<years_experience>7</years_experience>
<project_count>17</project_count>
</employee>
<employee id="2">
<name>Grace B1</name>
<age>59</age>
<city>Berlin</city>
<department>Engineering</department>
<salary>100066</salary>
<years_experience>11</years_experience>
<project_count>32</project_count>
</employee>
<employee id="3">
<name>Grace C2</name>
<age>64</age>
<city>Dubai</city>
<department>Engineering</department>
<salary>91727</salary>
<years_experience>9</years_experience>
<project_count>49</project_count>
</employee>
</employees>4. YAML
records:
- id: 1
name: "Diana A0"
age: 46
city: "London"
department: "Engineering"
salary: 141015
years_experience: 7
project_count: 17
- id: 2
name: "Grace B1"
age: 59
city: "Berlin"
department: "Engineering"
salary: 100066
years_experience: 11
project_count: 32
- id: 3
name: "Grace C2"
age: 64
city: "Dubai"
department: "Engineering"
salary: 91727
years_experience: 9
project_count: 495. HTML
<h1>Employee Records</h1>
<table>
<thead>
<tr>
<th>id</th>
<th>name</th>
<th>age</th>
<th>city</th>
<th>department</th>
<th>salary</th>
<th>years_experience</th>
<th>project_count</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>Diana A0</td>
<td>46</td>
<td>London</td>
<td>Engineering</td>
<td>141015</td>
<td>7</td>
<td>17</td>
</tr>
<tr>
<td>2</td>
<td>Grace B1</td>
<td>59</td>
<td>Berlin</td>
<td>Engineering</td>
<td>100066</td>
<td>11</td>
<td>32</td>
</tr>
<tr>
<td>3</td>
<td>Grace C2</td>
<td>64</td>
<td>Dubai</td>
<td>Engineering</td>
<td>91727</td>
<td>9</td>
<td>49</td>
</tr>
</tbody>
</table>6. Markdown Table
| id | name | age | city | department | salary | years_experience | project_count |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | Diana A0 | 46 | London | Engineering | 141015 | 7 | 17 |
| 2 | Grace B1 | 59 | Berlin | Engineering | 100066 | 11 | 32 |
| 3 | Grace C2 | 64 | Dubai | Engineering | 91727 | 9 | 49 |7. Markdown KV
# Employee Database
## Record 1
```
id: 1
name: Charlie A0
age: 56
city: New York
department: Operations
salary: 67896
years_experience: 7
project_count: 1
```
## Record 2
```
id: 2
name: Grace B1
age: 59
city: Mumbai
department: Marketing
salary: 47248
years_experience: 0
project_count: 43
```
## Record 3
```
id: 3
name: Eve C2
age: 50
city: Singapore
department: Sales
salary: 102915
years_experience: 14
project_count: 11
```8. INI
[employee_1]
id = 1
name = Diana A0
age = 46
city = London
department = Engineering
salary = 141015
years_experience = 7
project_count = 17
[employee_2]
id = 2
name = Grace B1
age = 59
city = Berlin
department = Engineering
salary = 100066
years_experience = 11
project_count = 32
[employee_3]
id = 3
name = Grace C2
age = 64
city = Dubai
department = Engineering
salary = 91727
years_experience = 9
project_count = 499. Pipe-Delimited
id: 1 | name: Diana A0 | age: 46 | city: London | department: Engineering | salary: 141015 | years_experience: 7 | project_count: 17
id: 2 | name: Grace B1 | age: 59 | city: Berlin | department: Engineering | salary: 100066 | years_experience: 11 | project_count: 32
id: 3 | name: Grace C2 | age: 64 | city: Dubai | department: Engineering | salary: 91727 | years_experience: 9 | project_count: 4910. JSONL
{"id": 1, "name": "Diana A0", "age": 46, "city": "London", "department": "Engineering", "salary": 141015, "years_experience": 7, "project_count": 17}
{"id": 2, "name": "Grace B1", "age": 59, "city": "Berlin", "department": "Engineering", "salary": 100066, "years_experience": 11, "project_count": 32}
{"id": 3, "name": "Grace C2", "age": 64, "city": "Dubai", "department": "Engineering", "salary": 91727, "years_experience": 9, "project_count": 49}11. Natural Language
Employee Records Summary:
Diana A0 (ID: 1) is a 46-year-old employee working in the Engineering department in London. They earn $141,015 with 7 years of experience and have completed 17 projects.
Grace B1 (ID: 2) is a 59-year-old employee working in the Engineering department in Berlin. They earn $100,066 with 11 years of experience and have completed 32 projects.
Grace C2 (ID: 3) is a 64-year-old employee working in the Engineering department in Dubai. They earn $91,727 with 9 years of experience and have completed 49 projects.Practical Guidance
Based on the results of our experiment:
- If you make heavy use of tabular data, consider testing whether transforming that data into a different format gives you improved accuracy.
- Markdown-KV looks a good default in situations where accuracy is paramount.
- Consider markdown tables when you need a balance between readability and cost.
- Be wary of defaulting to CSV or JSONL - these common formats could hurt your system’s accuracy.
Limitations and Areas for Further Study
- Models & Providers: We only tested OpenAI’s GPT-4.1 nano. Other models, particularly those from other providers, may work best with different data formats (e.g. whatever format was used most in training that model.)
- Data Content: We only tested one pattern of data. Results might be different with other patterns of data.
- Data Structure: We only tested straightforward tabular data. It would be interesting to test with nested data such as JSON configs and tables with merged cells. Update: We’ve now published some findings regarding this.
- Table Size & Header Repetition: To stress the model we used a relatively large table of data and didn’t repeat any headers. We’d expect smaller tables and/or repeated header rows to lead to higher accuracy, particularly for CSV, HTML and markdown table formats (the ones that involve header rows.)
- Question Type: Each of our test questions corresponded to retrieving the value of a field in a given record. It would be interesting to test other types of question.
Closing Thoughts
We were surprised by how much the input data format seemed to matter.
Our findings suggest that implementing simple data transformations could, in some cases, be an easy way to improve the accuracy of your LLM-based systems.
We’re keen to investigate this topic more.
Update: We have now published some findings regarding the related question of which nested data formats LLMs understand best.Subscribe to our newsletter if you’d like to be updated when we have new findings about this or other topics relating to improving AI agents.
Enjoyed This Article?
Get more tactical AI agent insights delivered to your inbox
We respect your privacy. Unsubscribe at any time.